 Vestíbulo de acceso al Tokyo Data Center. Foto: alexkane, Flickr
Vestíbulo de acceso al Tokyo Data Center. Foto: alexkane, FlickrLa aparición a mitad del siglo XX de la tecnología informática, del ordenador o computador personal, y finalmente Internet, ha supuesto un vuelco radica en la forma como se gestiona y difunde el conocimiento adquirido. De la plasmación de las ideas y los datos sobre páginas de papel hemos pasado en un instante histórico a una acelerada digitalización de toda la información disponible. Sin apenas darnos cuenta hemos empezado a acumular el saber histórico junto con otros tipos de información en oscuros espacios desconocidos. Lugares que nos son casi invisibles y sobre los cuales sería conveniente reflexionar.
<
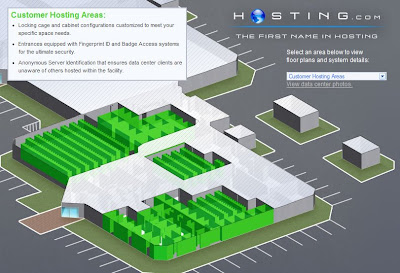 Esquema del centro de almacenaje de datos de la empresa Hosting.com en Irvine, California
Esquema del centro de almacenaje de datos de la empresa Hosting.com en Irvine, California
Lo cierto es que las inmensas galaxias y océanos de datos, cuyo tamaño se duplica cada cierto número de años en una extraña ley de Hubble, son todavía irrelevantes a la hora de la extracción de conclusiones específicas sobre el comportamiento íntimo de los individuos. Esto lo ha explicado muy acertadamente Simon R Garfinkel, experto informático en seguridad digital de la marina estadounidense, en un número reciente de la revista Scientific American (Investigación y Ciencia, Noviembre de 2008). Los algoritmos para la resolución de identidades, fusión de datos, y análisis cruzado orientados a tratar las gigantescas disponibilidades de información son todavía incapaces de extraer antecedentes fiables de una persona determinada. Ello, más allá de la identificación de su fecha de nacimiento, número de teléfono, etc., al generarse errores en una proporción muchísimo mayor a la de aciertos. La parafernalia de control personal difundida por la imaginería hollywoodiense, en películas como la Identidad Bourne, está todavía lejos de ser una realidad aunque el esfuerzo existe y esté en camino.
En los inicios de la nueva era de la información, como la ha bautizado Manuel Castells en su famosa trilogía, los ordenadores eran unos monstruosos artilugios que ocupaban centenares de metros cuadrados en unas condiciones tecnológicas precarias.
El surgimiento del ordenador personal y de los sistemas de almacenaje mediante cintas y discos magnéticos, produjo un vuelco fundamental que condujo a la extensión planetaria de las tecnologías informáticas. Nuevos conceptos extraídos del griego y con reminiscencias arcaicas, el Megabyte y sus herederos, Gygas y Teras, fueron haciéndose cotidianos para expresar la capacidad de almacenaje de datos en un espacio cada vez más reducido. El futuro Peta reflejará una capacidad de acceso a un volumen de información que no hubieran podido soñar nuestros padres. Toda la historia acumulada en un dispositivo que cabrá en la palma de la mano.
La traducción digital del saber atesorado físicamente es un proceso que aun sigue en curso. Cientos de instituciones públicas y privadas están actualmente digitalizando sus posesiones para hacer realidad aquella colección universal completa de textos que se imaginó Jorge Luís Borges en uno de sus geniales relatos, la biblioteca de Babel. Ha sido la conceptualización de lo que llaman contenidos que se archivan, textos y datos de todo tipo de los cuales las imágenes en movimiento lo que ha constituido la última frontera de la acumulación del conocimiento.
La aparición de Internet y su utilización masiva, hace escasamente una quincena de años, ha supuesto a su vez un cambio radical en la forma en que se accede y gestiona la información disponible. Un espacio inmaterial construido masivamente por las persistentes aportaciones de millones de personas en todo el mundo, realizadas de una manera anárquica y libre, sin que hasta ahora se vislumbre un control u orientación clara.
Un elemento relacionado con la información digital y que paulatinamente se ha ido configurando como crucial a los efectos económicos, es el lugar donde se guardan las aportaciones individuales, constantemente acopiadas y como se tratan masivamente los datos que flotan espontáneamente en Internet. La esfera política todavía no se ha percatado de este hecho esencial, para la independencia y la competitividad de las sociedades. La acumulación masiva de datos está teniendo lugar delante de nuestras narices a una velocidad de vértigo y sin que, por lo general, nos demos cuenta.  Proyecto de la empresa Terremark para el Neutral Access Point de las Américas en Miami
Proyecto de la empresa Terremark para el Neutral Access Point de las Américas en Miami
Empresas estadounidenses lideran este proceso de acumulación de conocimiento, en primera instancia con objetivos económicos. Por ejemplo, Microsoft o Google en el universo de su gestión genérica o EBay o Amazon en el acopio de datos personales sobre gustos y aspiraciones, lo cual les está generando un poder de influencia extraordinario sobre las decisiones individuales de cientos de millones de personas.
En un reciente informe del semanario Economist, titulado Donde la nube se encuentra con la tierra, se identificaba estos esfuerzos como un proceso de construcción empresarial similar al que durante la primera mitad del siglo XX llevaron a cabo las compañías de suministro de aguas, eléctricas y de telecomunicaciones. En ese trabajo se señalaba la reciente y creciente transformación hacia la ubicuidad de las utilidades que se suelen emplear para la interacción con la información digital. Este proceso lo han bautizado los anglosajones como cloud computing: Informática en nube, tratamiento etéreo o virtualización de la información en traducciones apresuradas.
La cuestión es que programas y servicios como el tratamiento de textos y la gestión del correo electrónico van a dejar de depender de la adquisición de determinados paquetes informáticos a instalar en las maquinas de nuestra propiedad para poder disponer de ellos en cualquier lugar que disponga de un acceso a la red telefónica o Internet. Con ello nuestros datos estarán globalmente disponibles pero no serán localmente gestionados y con ello, su control y disposición lo repartiremos con quienes han suministrado el servicio. La generación de bases de datos gigantescas a partir de esta valiosa información permitirá gestionar la oferta personalizada de productos en un proceso de manipulación creciente de nuestras necesidades al margen de la obtención de servicios que resultan ya irresistibles.
Amazon, el gigante de la venta en la red, es el que señaló el camino cuando en 2006 comercializó la oferta de un paquete de programas denominado Amazon Web Service, que permite la creación de una base de datos individual en la que acumular y poner a disposición de grupos y empresas recursos sin necesidad de tener una base física propia.
Otras empresas americanas han apostado por esta línea de negocio que supone la generación de una legión de centros de datos con millares de ordenadores interconectados. Google construye aceleradamente en estos momentos una infraestructura global formada ya por más de 40 centros de datos repartidos por todo el mundo que albergan más de dos millones de ordenadores. Microsoft está conectando a su red global una proporción de 35.000 nuevos servidores cada mes.

Vista aérea de un centro de datos en Quincy, Massachussets. Foto: cellanr, Flickr
Algunos lugares, como en las cercanías de Seattle en el estado norteamericano de Washington, se han convertido en verdaderos santuarios de datos, en una prolongación espacial de las sedes centrales de esas empresas especializadas en la gestión de la información y los servicios asociados.
La localización de centros de datos, o mejor dicho la generación de nuevas urbanizaciones especializadas, debe responder a requisitos estrictos y que dependen de la fiabilidad, eficacia y economía de las infraestructuras disponibles en el lugar. En muchas partes del mundo, algunos ya han percibido el importante negocio que supone la gestión informática de bases masivas de datos y aspiran a atraer la localización de estas fuentes de riqueza.
Entre los condicionantes esenciales para la localización de centros de datos está el suministro de energía disponible en cantidad creciente y muy barata porque tanto el funcionamiento de los propios ordenadores, su acumulación progresiva como la refrigeración necesaria para la disipación del calor asociado, generan un consumo muy elevado de electricidad.
Otra cuestión importante es la disponibilidad de una población culturalmente preparada y con capacidad para el manejo de las tecnologías y sistemas apropiados junto con conexiones próximas y eficientes a la red telemática global
La gestión de miles de ordenadores en funcionamiento permanente y unas condiciones necesariamente estables de temperatura ambiente ha convertido a la producción de enfriamiento regular y constante en el elemento básico de diseño de estos centros de datos o granjas de servidores como también son conocidos
Precisamente, países como Islandia se han revelado una buena localización al disponer de un clima extremadamente frío que hace superflua la refrigeración y contar además con importantes fuentes energéticas geotérmicas de bajo coste basadas en el vulcanismo superficial existente. Esta isla del Atlántico Norte aporta también otras ventajas evidentes como son una población con un buen nivel de formación y su posición relativamente cercana al eje de comunicaciones telemáticas más importante del mundo, el que conecta la costa Oeste americana con el sur de Inglaterra y Europa.

Localización de los principales cables telefónicos submarinos que conectan Europa y América. Fuente: Telegeography, 2008
IBM ha diseñado módulos acoplables de ordenadores, instalados en contenedores estándar, capaces de incrementar la capacidad de un centro de datos con enorme facilidad. Google ha puesto también sobre el tapete de la discusión sobre el futuro de estas instalaciones varias ideas para mejorar su eficiencia y economía. Una de ellas consistiría en localizar estos servicios en alta mar, alimentando sus necesidades energéticas con la fuerza de las olas y producir la refrigeración necesaria a partir de la renovación constante con fría agua de mar. Un diseño preliminar de esta idea circula ya por la red, definido como una especie de barco factoría anclado en medio del océano que albergaría cientos de ordenadores. 
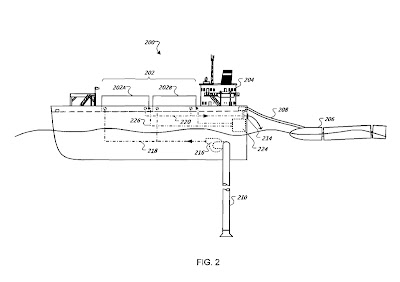 Ejemplos de soluciones para centros modulares de IBM y barco de datos propuesto por Google
Ejemplos de soluciones para centros modulares de IBM y barco de datos propuesto por Google
Muchas dudas se suscitan a los profanos en estas cuestiones. El problema es saber donde está el control y la responsabilidad final sobre la disposición de esta vasta información. Conocer quien ejerce algún tipo de atribución y porqué, sobre datos sensibles de millones de personas que no lo saben o han autorizado de una manera discutible su acumulación.
Por ello, los estados y las regiones deberían tomar consciencia de este problema y exigir la construcción de las llamadas eufemísticamente nubes locales de datos que puedan ser administradas y controladas por las propias colectividades más cercanas y no extender el peligro de que nuestra información sea gestionada y gobernada con fines exclusivamente económicos desde remotos lugares indefinidos.






Este comentario ha sido eliminado por un administrador del blog.